
머신러닝을 통해서 기계를 학습시켜 결과물로 모델을 만들어 모델로 값을 예측시키는 것입니다
머신러닝이란?
- 기계가 데이터로부터 학습하도록 프로그래밍하는 과학/기술 분야 입니다
- 머신 러닝을 사용하면 대용량 데이터를 분석하여 인간이 보기 힘든 패턴을 발견할 수 있습니다
머신러닝이 뛰어난 분야
- 머신러닝은 기존 솔루션이 많은 수동 조정 (hand-tuning) 또는 긴 규칙 리스트가 필요한 문제를 잘 해결할 수 있습니다
- 유동적인 주변 환경에서 성능을 발휘할 수 있습니다
- 복잡한 문제와 대량의 데이터에 관한 통찰을 얻을 수 있습니다
머신러닝 시스템의 종류
앞서 머신러닝이 무엇이고 머신러닝이 어떤 방면에서 뛰어난지 확인하였습니다.
머신러닝은 여러 학습 방법이 있으며 각각의 학습 방법마다 특징이 서로 다릅니다.
● 사람의 감독하에 훈련하는 것인지 그렇지 않은 것인지에 따라서 다음과 같이 나뉩니다
✓ 지도 학습 supervised learning
✓ 비지도 학습 unsupervised learning
✓ 준지도 학습 semi-supervised learning
✓ 강화 학습 reinforcement learning
● 실시간으로 점진적인 학습을 하는지 아닌지에 따라서 나뉩니다
✓ 온라인 학습
✓ 배치. 학습
● 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처럼 훈련 데이터셋에서 패턴을
발견하여 예측 모델을 만드는 것인지에 따라서 나뉩니다.
✓ 사례 또는 인스턴스 기반 학습
✓ 모델 기반 학습
지도 학습
지도 학습에는 알고리즘에 주입하는 훈련 데이터에 레이블이라는 원하는 답이 포함됩니다.
즉 컴퓨터한테 문제의 정답을 보여줘서 다음 유사한 문제인 경우 학습한 정답을 예측하는 원리 입니다.
분류 Classification
대표적인 지도 학습을 이용한 작업으로는 분류가 있겠습니다.
- 예를 들어 고양이와 강아지를 분류하도록 사진과 정답을 미리 학습시켜 고양이 사진을 줬을 때 기계가 고양이라고 정답을 말하는 것이
분류 예시입니다.
회귀 Regression
또다른 지도 학습을 이용한 작업으로는 분류가 있습니다.
- 분류와 다르게 회귀는 예측 변수라 부르는 특성 (예: 주행거리, 연식, 브랜드 등)을 사용하여 값을 예측하는 것입니다.
- 예를 들어 다음과 같은 특성 값들과 정답 레이블이 있을 때 컴퓨터한테 15000km, 2000, 현대 일때는 200만원 정도의 값일거야~ 하고
훈련을 시키는 것입니다.
물론 분류와 다르게 15000km, 2000, 현대 일때는 200만원이야! 라고 정하는 것이 아닌 200만원 정도야~ 라고 추정합니다.
분류 시스템을 훈련하려면 예측 변수와 레이블이 포함된 데이터가 많이 필요합니다.
| 주행거리 | 연식 | 브랜드 | 가격 (정답) |
| 15000 | 2000 | 현대 | 200만원 |
| 20220 | 1997 | KIA | 150만원 |

지도 학습 알고리즘
지도 학습 알고리즘에는 다음과 같이 여러 알고리즘들이 존재합니다
- k-최근접 이웃
- 선형 회귀
- 로지스틱 회귀
- 서포트 벡터 머신 (SVM)
- 결정 트리와 랜덤 포레스트
- 신경망 (딥러닝)
비지도 학습
비지도 학습은 지도 학습과 달리 말 그대로 지도를 하지 않는, 기계에게 정답 레이블을 안주고 문제만 주는 것 입니다.
즉 비지도 학습은 기계가 아무런 도움 없이 학습을 해야합니다.
클러스터링
- 비지도 학습 작업인 clustering (클러스터링, 군집화)는 특정 유사한 데이터들 중 서로서로를 찾아내고 묶어내는 것입니다.
- 예를 들어 블로그 방문자에 관한 데이터가 많을 때, 유사한 방문자들로 그룹을 묶기 위해서 군집 알고리즘 실행이 필요합니다.
- 기계는 각 방문자들이 속한 그룹(정답 레이블)을 모르기 때문에 스스로 방문자 사이의 연결고리를 찾아야 합니다.
- 예, 방문자 중 40%는 남성, 만화책 선호, 저녁 방문, 20%는 젊고, 공상과학 선호, 주말 방문
- 계층 군집을 사용한다면 더 작은 그룹으로 세분화할 수 있습니다.
- 대표적으로 지도에서 일정 위치에 여러 📍이 존재한다면 묶어서 하나의 큰 원으로 표현하는 작업이 클러스터링이라 합니다.

시각화
- visualization (시각화)는 레이블이 없는 대규모의 고차원데이터를 넣으면 도식화가 가능한 2D나 3D 표현으로 만들어주는 것
- 이런 알고리즘은 간으한 한 구조를 그대로 유지하려 하므로 (예를 들어 입력 공간에서 떨어져 있던 클러스터는 시각화된 그래프에서 겹쳐지지 않게 유지) 데이터가 어떻게 조직되어 있는지 이해할 수 있고 예상하지 못한 패턴을 발견할 수 있습니다.
- 즉 인간이 100차원을 직접 표현할 수 없기 때문에 100차원같은 고차원의 데이터를 저차원의 데이터로 바꿔서 보여줍니다.
- 예로 아래 것들은 수십개의 특징값(특성값)이 존재할텐데 100개의 특징은 100차원 데이터로 표현하게 됩니다.
- 하지만 100차원의 데이터를 직접 인간이 표현하기 어렵기 때문에 시각화를 통해 아래와 같이 표현할 수 있게 됩니다.

차원 축소
- dimensionality reduction (차원 축소)의 목표는 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는 작업입니다.
- 차원 축소의 한 가지 방법은 상관 관계가 있는 여러 특성들을 하나로 합치는 것입니다.
- 예를 들어, 차 주행거리는 연식과 밀접하게 연관되어 있으므로 DR 알고리즘을 통해 차의 마모 정도를 나타내는 한 특성으로 합치는 것이 가능합니다. 이를 특성 추출이라고 합니다.
- ML 알고리즘에 데이터를 적용하기 전에 DR 알고리즘을 적용하여 데이터의 차원을 줄이는 것이 매우 유용할 수 있습니다. 이는 실행 속도가 빨라지고, 디스크/메모리를 적게 사용하며, 경우에 따라서 성능이 좋아지기도 합니다.
이상치 탐지
- 또 하나의 중요한 비지도 학습은 outlier detection이라고 합니다.
- 예를 들어 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제조 결함을 잡아내는 것을 의미하며
- 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는데 사용할 수 있습니다.
- 기계는 정상 인스턴스로 훈련하고 새로운 인스턴스가 주어질 경우 정상인지 이상치인지 판단합니다.
연관 규칙 학습
- association rule learning이라고 불리는 연간 규칙 학습은 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 것을 목표로 합니다
- 예를 들어 슈퍼마켓 운영자 입장에서 판매 기록을 분석하면 아마 바베큐 소스와 감자칩을 구매한 사람이 또한 스테이크를 구매하는 경향이 있다는 것을 찾을지도 모릅니다. -> 연관 있는 제품을 가까이 놓을 수 있음

준지도 학습
데이터에 각 데이터마다 레이블(정답)을 다는 것은 일반적으로 시간과 비용이 많이 들기 때문에 레이블(정답)이 없는 샘플이 많고 레이블된 샘플이 적은 경우가 많습니다. 어떤 알고리즘은 일부만 레이블(정답)이 있는 데이터를 다룰 수 있는데 이를 준지도 학습이라고 합니다.
- 준지도 학습은 일상생활에서도 현재 많이 사용되고 있습니다, 예를 들어 요로 사진을 찍었을 때 앨범에서 사람마다 레이블을 하나만 추가하면 사진에 있는 모든 사람의 이름을 알 수 있고, 검색을 통해서 편리하게 사진을 찾을 수 있습니다.
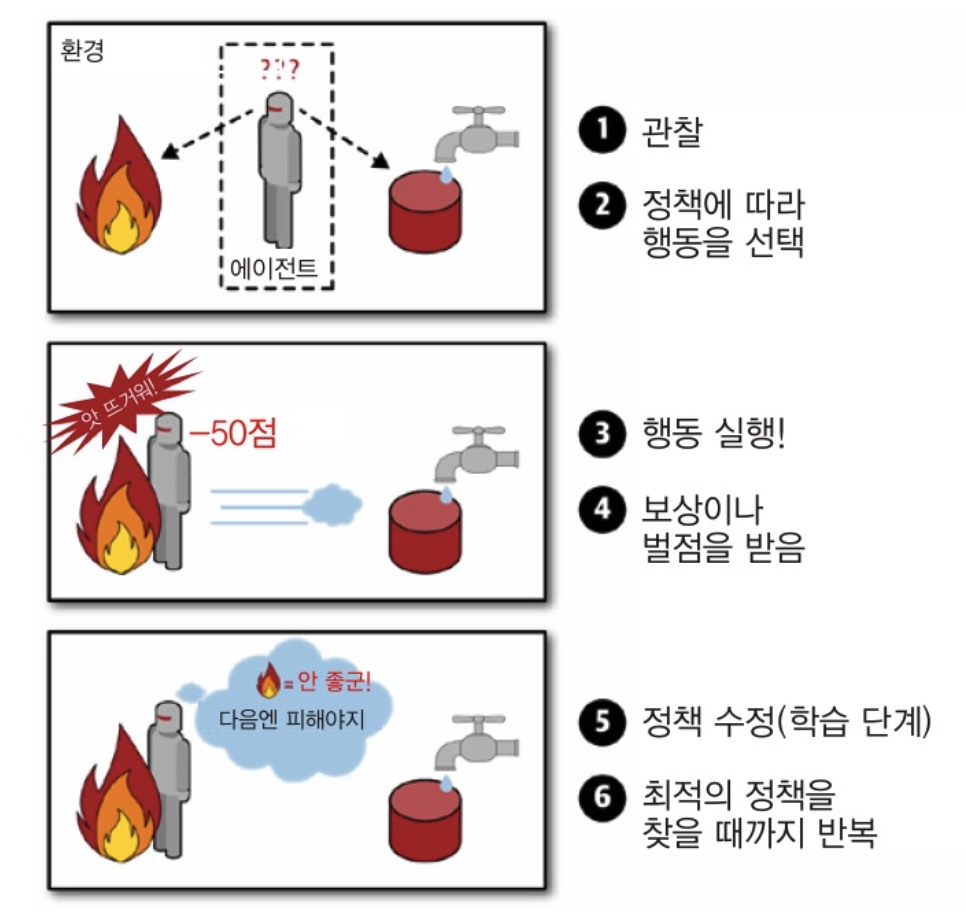
강화 학습
- 강화 학습은 기계가 환경을 관찰하고, 행동을 결정하고 실행하여, 그 대가로 보상 또는 벌점을 받는 개념의 학습입니다.
- 시간이 지나는 동안에 기계는 최대 보상을 받기 위한 '정책'을 스스로 학습해야합니다.
- 여기서 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의하는 것입니다.
- 강화학습을 적용된 예시로는 딥마인드에서 개발한 알파고나 보행 로봇 등이 있습니다
배치 학습 (오프라인 학습)
- 배치 학습에서는 시스템이 점진적으로 학습할 수 없습니다.
✓ 가용한 데이터를 모두 사용하여 훈련시켜야 합니다.
✓ 시간과 자원이 많이 소비하므로 오프라인에서 수행합니다
✓ 시스템을 훈련시킨 후에 제품에 적용하려면 추가 학습 없이 실행됩니다. - 새로운 데이터에 대해 학습하려면 처음부터 다시 훈련합니다
✓ (점진적 학습이 불가하므로 새로운 데이터 뿐만 아니라 이전 데이터를 포함한) 전체 데이터를 가지고 새로운버전의 시스템 훈련이
필요합니다
✓ 새 버전 시스템이 준비 되면 기존 시스템을 중지하고 새 시스템으로 교체해야 한다는 문제점이 있습니다. - ML 훈련, 평가, 런칭과 같은 전체 과정은 자동화가 가능합니다
✓ 훈련 시간이 많이 소요 되는 경우에는 일정 주기마다 훈련이 자동화됩니다.
✓ 급변하는 데이터에 적응이 필요할 때 능동적인 방법이 필요합니다 (예, 주식 가격 예측)

- 때로는 전체 데이터셋 훈련에 많은 컴퓨팅 자원이 필요합니다
✓ CPU, 메모리 공간, 디스크 공간, 디스크 I/O, 네트워크 I/O 등 컴퓨팅 자원이 필요합니다.
✓ 큰 데이터셋을 가지고 자주 배치 학습을 필요로 하는 시스템은 큰 비용이 발생합니다. - 자원이 제한된 시스템에서는 비효율적입니다
✓ 스마트폰, 로봇과 같이 자원이 제한된 시스템은 오히려 점진적(온라인) 학습이 효율적이라고 할 수 있습니다.
온라인 학습
- 점진적 학습이 가능합니다(1)
✓ 온라인 학습은 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킵니다.
✓ 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있습니다.

- 점진적 학습이 가능합니다(2)
✓ 컴퓨터 한대의 메모리가 다 들어갈 수 없을 정도로 큰 데이터셋 훈련을 위해 온라인 학습을 사용할 수도 있습니다.
-> 외부 메모리 학습
✓ 전체 데이터셋을 부분으로 쪼개어 각 부분에 대해 학습과정을 반복합니다.

- 온라인 학습은 연속적으로 데이터를 받고 (예를 들어 주식가격) 빠른 변화에 스스로 적응해야 하는 시스템에 적합합니다.
✓ 컴퓨팅 자원이 제한된 경우(예: 스마트폰)에도 좋은 선택입니다.
✓ 모델을 만들 때 실시간으로 학습했던 데이터셋(미니배치)을 학습이 끝난 이후에는 필요하지 않으므로 버릴 수 있습니다. - 온라인 학습에서 학습률이라는 중요한 파라미터가 존재합니다, 학습률은 변화하는 데이터엥 얼마나 빠르게 적응할 것인가를 결정하는 파라미터입니다.
✓ 높은 학습률은 데이터 변화에 빠른 대응이 가능하나, 이전 데이터를 빠르게 잊어버립니다. (항상 좋지만은 않습니다)
✓ 낮은 학습률은 변화에 둔감하나, 새 데이터 잡음이나 이상치(outlier)에 덜 민감합니다 (항상 나쁘지만은 않습니다)
인스턴스 기반 학습
- 가장 평범한 형태의 학습은 단순히 기억하기입니다. (예: 사용자가 스팸으로 지정한 메일과 동일한 메일들을 스팸으로 분류)
- 이렇게 하면 유사도 측정 방법이 필요합니다. 스팸 필터에서 활용 가능한 SM은 두 메일간 공통으로 포함된 단어의 수, 만약 스팸 메일과 공통으로 가진 단어가 '일정 수'보다 많으면 스팸으로 분류하는 형식으로 이루어질 수 있습니다.
- 가장 대표적인 인스턴스 기반 학습이 k-Nearest Neighbor (kNN, 최근접 이웃) 알고리즘입니다.

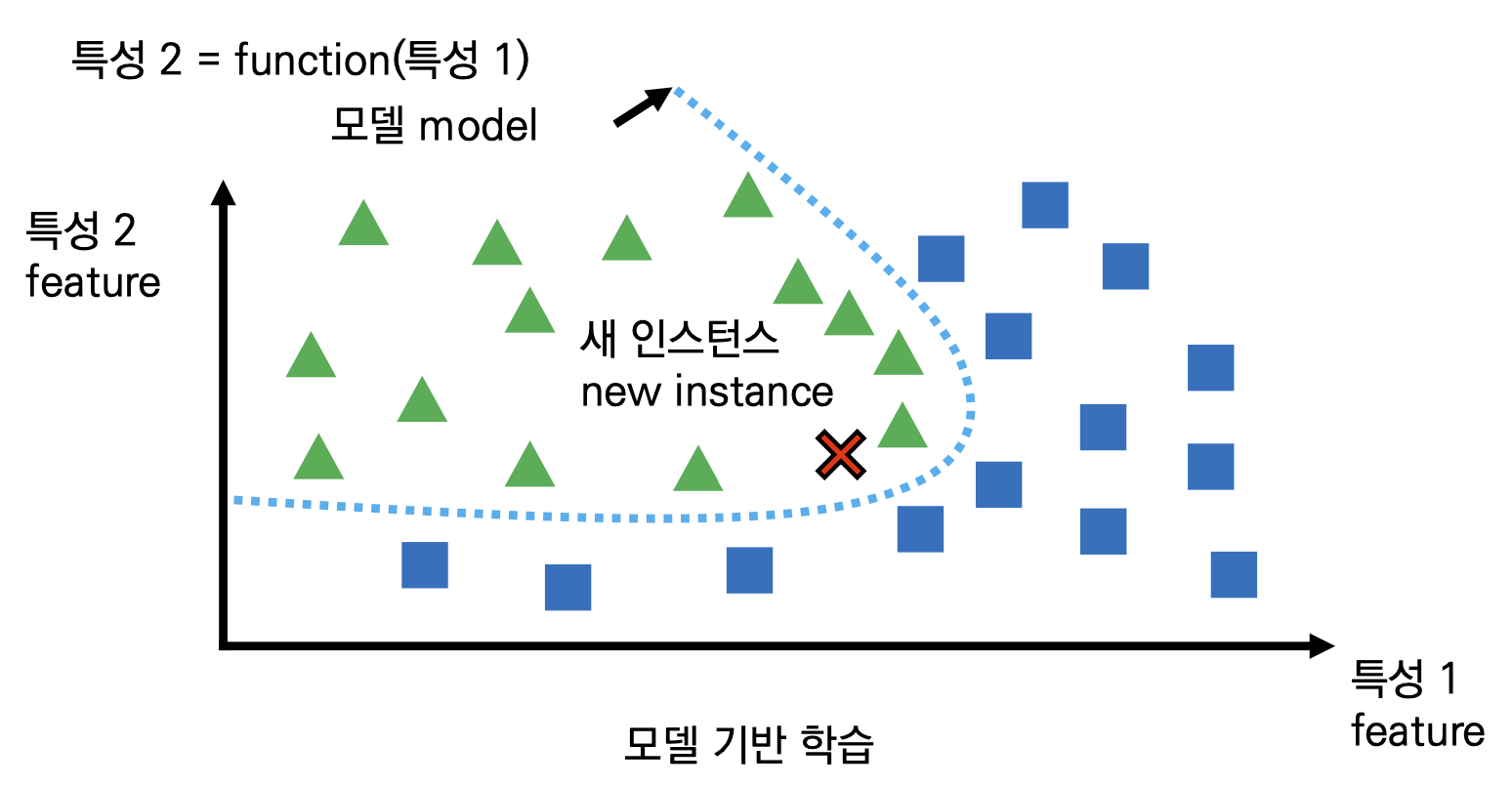
모델 기반 학습
- 일반화는 결국 새로운 데이터들이 왔을 때 학습 시스템이 잘 동작 하기 위하여 (예: 예측) 내가 알고 있는 사례들을 잘 정리하는 것 입니다.
- 인스턴스 기반 학습은 일반화를 '새 데이터가 올 때마다' SM을 활용하여 일반화를 적용합니다.
- 반면에 모델 기반 학습은 훈련 인스턴스들을 분석하여 모델을 생성하여 내가 알고 있는 사례들을 미리 정리합니다
-> 새 데이터가 오기 전에 일반화
머신러닝을 하기 위해서는?
- 문제 해결을 위해 ML 알고리즘은 충분한 데이터가 필요합니다. (많으면 많을수록 무조건 좋습니다)

- 일반화를 위해서 훈련 데이터가 새로운 데이터에 대한 대표성이 충분해야 합니다.
✓ 샘플링 잡음 (sampling noise)
- 만약 샘플이 너무 작으면, 우연에 의해 대표성이 없는 데이터를 가지고 학습할 수 있습니다
✓ 샘플링 편향 (sampling bias)
- 비록 매우 큰 샘플도 추출 방법이 잘못되면 대표성을 가지지 못할 수도 있습니다 - 데이터에 오류, 이상치, 잡음이 많으면 기계는 데이터에 내재된 패턴을 찾을 수 없으며 새로운 데이터에 적용할 때 잘 동작하지 않습니다, 따라서 옮바른 데이터를 사용하는 것이 중요합니다.
✓ 만일 정제되지 않은 데이터셋을 사용한다면 일부 특성이 필요 없다고 생각되면 해당 특성을 지우거나 값이 빠져있을 때 대체값을
넣는 방법 등을 사용해야 합니다. - ML에서의 핵심은 훈련에 사용할 특성 집합을 찾아내는 것으로 이를 Feature engineering (피처 엔지니어링, 특성 공학)이라고 합니다.
✓ 특성 선택 (feature selection)
- 가지고 있는 특성들 중에 훈련에 가장 유용한 특성을 선택하는 것
✓ 특성 추출 (feature extraction)
- 특성을 결합하여 더욱 유용한 특성을 만드는 것 (차원 축소 알고리즘 예)
- 학습에 도움이 되는 '특성들의 조합'을 찾는 것도 특성 추출이라고 말할 수 있습니다.
머신러닝에서 조심해야하는 것?
- 훈련 데이터 과대 적합을 조심해야 합니다. Overfitting (오버피팅, 과대적합)
✓ 외국인에 대한 과대한 택시 요금이 국가 전체 택시 운전사들에 대해 나쁜 인식으로 확대될 수 있듯이, 과도한 일반화로 인해
컴퓨터도 같은 실수를 할 수 있게 됩니다.
✓ Overfitting (오버피팅, 과대적합)이란 훈련시킨 훈련 데이터에는 매우 잘 동작하지만 일반성이 떨어진느 현상을 의미합니다. - 오버피팅의 위험을 줄이기 위해서 모델에 규제를 사용하여 제약을 가하는 방법이 있습니다.
- 규제란 모델을 단순화 하기 위해 제약을 가하는 것입니다.
- 만약 삶의 만족도를 계산하는 공식이 다음과 같다고 가정합니다
- 삶의 만족도 = ⍬0 + ⍬0 X 1인당 GDP -> 절편 ⍬0, 기울기 ⍬1
- 기울기 ⍬1 = 0으로 강제 한다면? 단순한 평균값 구하기가 될 것입니다. (DOF는 1)
- 기울기 ⍬1 = 0을 수정하되 작은 값을 갖도록 유지하게 된다면 (DOF는 1과 2 사이 정도가 됩니다)
DOF(Degree of Freedom, 자유도): 통계와 모델링에서 중요한 개념으로, 모델의 유연성과 복잡성을 설명하는 데 사용됩니다
오버피팅 해결하기
규제는 오버피팅 되는 것을 방지하기 위해서 사용되는데 학습하는 동안 규제의 정도는 하이퍼파라미터가 결정합니다.
- 하이퍼파라미터는 학습하는 동안 '모델에 대한 규제의 정도'를 결정하게 해주는 '제어 파라미터' 역할을 합니다.
- 하이퍼파라미터는 학습 알고리즘으로부터 영향을 받지 않으며, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아있습니다.
- 규제 하이퍼 파라미터를 매우 큰 값으로 지정하면 (기울기가 0에 가까운) 거의 평편한 모델을 얻게 됩니다.
- 하이퍼파라미터 ⍺를 찾는 것이 사용자가 해야하는 것입니다.
훈련 데이터 과소적합
- 과소적합은 너무 단순한 모델은 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 일어납니다. -> underfitting (과소적합)
- 예를 들어 삶의 만족도에 대한 선형 모델은 과소적합되기 쉽습니다, 현실은 이 모델보다 더 복잡하므로.
- 언더피팅 해결 방법은 다음과 같습니다.
✓ 모델 파라미터가 더 많은 효과적인 모델을 선택합니다
✓ 학습 알고리즘에 더 효과적인 특성을 제공합니다 (특성 공학)
✓ 모델의 제약을 줄입니다
모델 테스트하기
훈련시킨 모델을 테스트 하기 위해서는 해당 모델이 잘 훈련 되었는지를 확인해야합니다. 만약 1개의 데이터로 한번 훈련했다고 모든 새로운 데이터에도 같은 성능을 발휘할 수 없기 때문에 조심해야합니다.
- 훈련 데이터를 훈련 셋과 테스트 셋으로 나눕니다. (일반적으로 훈련셋 80 : 테스트 셋 20 으로 나눕니다)
✓ 훈련 셋은 모델 학습에 사용
✓ 테스트 셋은 모델 테스트에 사용 - 모델을 테스트하기 위해서는 주로 교차 검증 (cross-validation) 기법을 사용합니다
✓ 검증 셋으로 너무 많은 양의 데이터를 뺏기지 않기 위해 사용합니다
✓ 훈련 셋을 여러 서브셋으로 나누고 일정 조합으로 모델을 훈련, 나머지로 검증합니다
✓ 모델과 하이퍼파라미터가 선택되면 전체 훈련 데이터로 최종 모델을 훈련하고 테스트 셋으로 일반화 오차를 측정합니다.
'AI > Machine Learning' 카테고리의 다른 글
| 사이킷런 scikit-learn 이란? (0) | 2024.07.09 |
|---|---|
| 여러 개의 레이블을 갖는 하나의 데이터 분류하기 - 다중 레이블 분류 (2) | 2024.07.08 |
| 머신러닝 분류 (숫자 예측) (0) | 2024.07.07 |
| 머신러닝 모델 튜닝하기 (0) | 2024.06.28 |
| 머신러닝 회귀 (집값 예측하기) (0) | 2024.06.27 |